
LiDAR & vision fusion
Unified multimodal perception
Dense clouds plus RGB cues

Spatiotemporal sync: shared time base and extrinsics align every cloud with its image frame.
Depth + texture fusion: combine geometric and appearance cues for harder scenes.
Detection / segmentation outputs for cranes, gates, and safety logic.
Open inference APIs for your runtime and retraining loops.
HOW IT WORKS
How it works

-
Synchronized capture
Common time base and extrinsics align every cloud with its image pair.
-
Feature- or decision-level fusion
Balance latency and accuracy per use case.
-
Deploy & active learning
Edge or server runtimes with pipelines to ingest hard examples.
ARCHITECTURE
System diagram
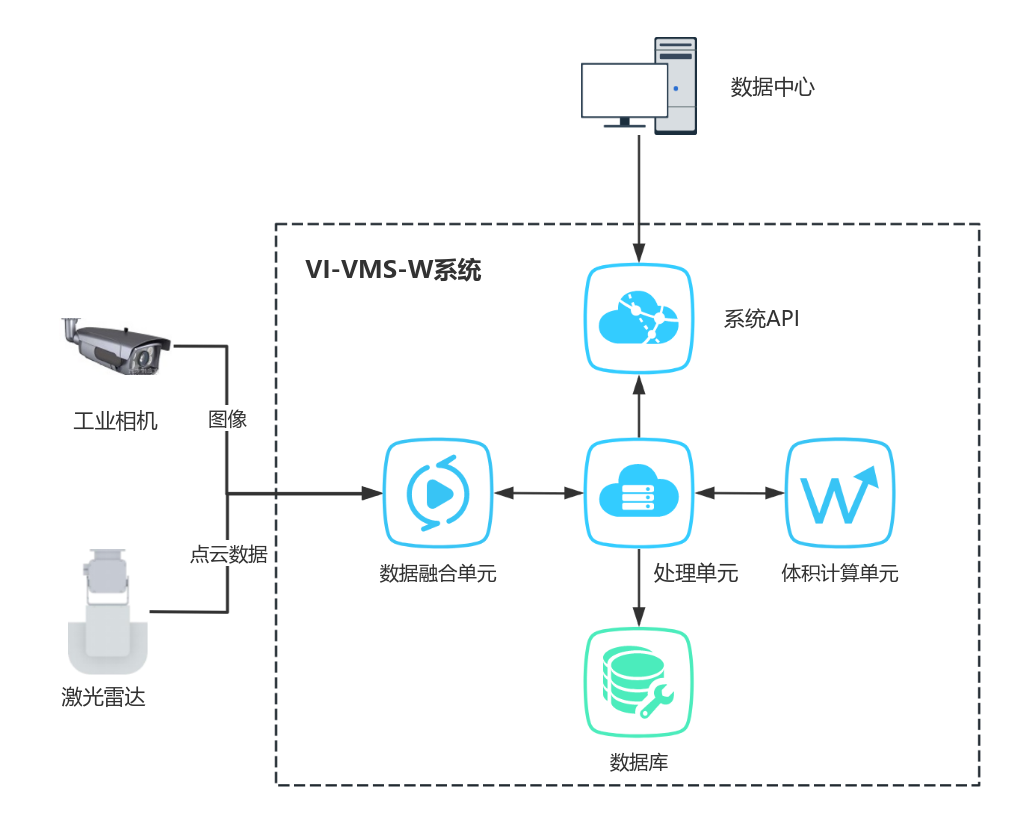
-
Harsh-scene robustness
Glare, dust, and partial occlusion handled with fused cues.
-
Tunable fusion
Shift emphasis between LiDAR- or vision-led stacks.
-
Reuse across scenes
Same framework extends to perimeter, loading, and mobility.
-
Engineering toolkit
Calibration, evaluation, and ops tooling for long-term iteration.
Scope a fusion pilot
Share classes, frame rate, and compute—we size sensors and algorithm scope.
Contact us